Creating a Horoscope Generator in Dutch by fine-tuning a GPT-2 model

The aim of this article is to explain how an AI model can be trained to generate horoscopes written in the Dutch language. The article will combine the use of Python, the art of web-scraping and a pre-trained GPT-2 model together with a bit of story telling to take you on a journey from concept to an actual implementation. A basic knowledge of Python is recommended and it is written for people who are interested in the application of AI to real use-cases.
A working demo can be found at horoscope.wesselhuising.nl (see link below). The code for the tool can be found at my github repo.
Interlude
During another evening in the midst of the Corona pandemic combined with the extreme measures resulting in a curfew, I was doomed to watch television together with my girlfriend, again. Just like every evening before, nothing on the linear programming was interesting to watch because of the simple reason that the Dutch television generally consists of accessible entertainment shows (I am talking to you John de Mol). Luckily, it’s 2021 and there is more than just linear television so by scrolling through the apps of the generic streaming providers I was able to find one television show which always works for me: “Dit Was Het Nieuws”. A satirical show discussing the news from last week.
This weeks bizarre highlight came from two “famous” dutch women named Lieke and Jetteke van Lexmond (yes, they are related). They seem to be very into astrology (or black magic for the ones who never heard the term before) and this is not even the fun part. The show aired a videoclip of the two using a whole lot of words to explain how they predicted the attack on the United States Capitol by a big group of lunatics. How? Because the planet Mars transits in Taurus and that seems to be a very heavy transition.This whole event has us laughing our asses off and totally made my day. As I lay in bed that evening and we discussed what we had just witnessed, my girlfriend mentioned to me:
I have a lot of friends who have these horoscope applications on their mobile phones giving them daily horoscopes and yes, they do read and apply them.
We discussed further in what became a rather heated conversation about the stupidity of those generic daily horoscopes, but it concluded with my girlfriend posing one provocative question:
What if you could just generate horoscopes, if they are not doing that already, and sell them as they are personalised per day?
Of course it is pure capitalism at its finest and slightly unethical (so is the commercialisation of astrology) but I felt it was worth the experiment. The next morning I dived into the matter and the question quickly refined to a more classy hypothesis:
Is it possible to create a horoscope generator by retraining a GPT-2 model, in Dutch?
This article aims to show the reader how a model, capable of generating text, like GPT-2 can be used for generating computer made horoscopes using web-scraped Dutch text snippets and a open-source pre-trained Dutch model.
- The 🤗 framework
- The architecture of a Transformer
- The GTP-2 Model by OpenAI
- Creating a Dutch horoscope dataset
- Finding a pre-trained Dutch language model
- Retraining the pre-trained model
- Generating new horoscopes written in Dutch
The 🤗 framework
This project will make use of a framework called 🤗. Yes, the framework is written like the “hugging face” emoji. But for the sake of keeping your brain from melting while reading the article, I will replace the 🤗 emoji with the actual words Hugging Face.
The Hugging Face framework (they call it an ecosystem) consists of several packages written in Python and every package represents a conceptual component of the ecosystem (Transformers, Datasets, Tokenizers and Accelerate). This article will mainly focus on the Transformer package and a bit on the Tokenizers package.
All Language Models (LM) supplied by the Hugging Face framework are Transformer based, as these models are using the Transformer architecture. That is why the package within the framework containing multiple model architectures is called transformers. These Transformers are trained on huge amount of raw text, as these enormous amounts of raw texts that are used as the input. These Transformers are trained in a self-supervised way which is a fancy way of stating that the input data does not have to be labeled by a human (like you and me) but creates the label (the objective) automatically by using some good old logic. Therefore, the Transformer learns a deeper statistical understanding of the input texts that has been fed to the LM but unfortunately this understanding is generic and not optimised for specifics tasks (fine, it might need some help from humans for this part).
Transfer Learning
This process of using a general pre-trained model and fine-tuning the LM for a specific task using human-annotated labels is called “Transfer Learning”. Transfer Learning is the concept taking a fully trained model (which understands a specific domain, like generating Dutch texts) trained for a generalised objective and use its knowledge to subsequently fine-tune the understanding for a specific task. More technically, Transfer Learning applies the idea of sharing weights of pre-trained language models and improving those weights for specific tasks, with a goal to minimize the computation costs.
The architecture of a Transformer
Before moving on, you need to know a bit about the architecture of a Transformer. I will post an image of the architecture from the original paper but I will not bore you with the actual contents of the layers. The one thing you should know is that a Transformer consists of two parts: an encoder and a decoder.

The encoder
The encoder part receives the input and builds representations of the input, which will be considered as the “features”. The encoder part is therefore used to optimize the model to acquire understanding from the inputs. The encoder part is mainly used for classification tasks like “sentence classification” (is this sentence happy or angry) and named entity recognition (hey, this entity “pils” seems to be some kind of beer).
The decoder
The decoder part also receives an input but is the lucky one to be able to combine the input with the features which have been outputted from the encoder. This combined input can be used to generate outputs as the decoder part is optimised to do so. The decoder part is therefore mainly used for text generation tasks.
The GTP-2 Model by OpenAI
The model I have used to generate text is the GTP-2 model developed by OpenAI. As this model is used to generate text the GTP-2 model only uses the decoder part of the Transformer architecture. The GTP-2 model was trained on a mind-blowing 40GB (8 million scraped webpages) dataset named “WebText” which the OpenAI researchers created themselves by crawling the internet using web-scraping. The training of the model resulted in having 1.5 billion parameters. The model is trained with the objective to predict the next word based on the input consisting of one or more words (you could call this the previous words in the sentence). The smallest variant of the trained GPT-2 takes up to 500MBs while the largest GPT-2 variant is 13 times the size which therefore is around 6.5 GBs in storage space.
Fun fact: there is already a GPT-3 which is not published because the risk of misuse (although OpenAI does commercially provide a API). OpenAI was in fact already hesitant to publish the GPT-2 weights but they seemingly did anyway, so that’s why I am going to use it today for creating horoscopes.
As GPT-2 is a decoder model, it uses its input to predict the the next word in the sentence. Its “attention layer” makes sure the Transformer can only access words preceding the word it should make a prediction for. Therefore, it can self-supervise its own training by only using raw texts as the input. The Transformer just keeps adding words to the input sentence and because of the texts being known, it is easy to validate the predicted word based on the known input texts. For every prediction it outputs a probability for every word known to the model. I will stop here before you will all close this article because of losing interest. Let’s get to the coding now.
Creating a Dutch horoscope dataset
This is the time to gather the raw texts for the Transformer to use for fine-tuning. My previous article “How to find your perfect apartment using a web-scraper written in Python” explains how to scrape the web and this technique will come in handy for this exercise as well (and I can finally plug the article again).
Using Scrapy, a Python package, I decided to scrape for generic daily horoscopes. I searched around on the Google and I found four sites which seemed to be ready to be violated by my scraping skills. I will show one piece of code which is a nice example how to scrape multiple URLs based on parameters in the link itself.
This script first generates all possible combinations of URLs which in theory could contain a daily horoscope text. This way of working is called ‘brute force’ and to be honest, is not the best approach for recurrent use. As this script is ran just one time only, I think it’s an acceptable solution. There are ways to calculate the day of the week based on the date using a default Python module named “time”. The superloop generates for every possible combination of day, month, zodiac sign and name of the day of the week a URL and pushes the formatted URL to the parse method using the yield function.
My dataset
After some long hours, frustration and URLs with loose ends, I managed to get to a decent dataset ready for some fine-tuning. I scraped four websites and ended with a dataset consisting of 9323 different original Dutch horoscopes. Before moving on into selecting the right general pre-trained model and stealing their weights for finetuning, I had to apply some minor pre-processing and some splitting of the dataset into train and test sets.
As the code shows, the most important column text is cleaned using the simple built-in function strip. The full pandas dataframe is loaded into a Dataset object from the datasets python package. The Dataset object has a built-in method to split the data, probably stolen from the scikit-learn toolkit as the API is the same. By setting the seed to a random number, I can make sure the splits are done in the same manner including the shuffling whenever the command is executed with the same dataset (comes in handy whenever you want to replicate one of the experiments later on). I wrote down the intestines of the dataset_split variable to the end as a comment in the above script to make sure that there is some sort of feeling of having the overview from a readers perspective.
As you can see the dataset_split variable contains a DataSetDict object with two keys. One for the training set and the other for the testing set. The features shown are the columns from the original pandas dataset including a extra meta-field concerning the length of both sets.
Finding a pre-trained Dutch language model
One crucial part of this use-case is finding a good pre-trained model containing a statistical understanding (lexical embeddings) of the Dutch language. I might be able to do it myself but like I stated before; it takes a lot of computational resources and therefore I can use this argument to hide my laziness. Luckily for me, other people still have dreams and ambitions.
Big Shout Out to the guys, Wietse de Vries and Malvina Nissim, from the University of Groningen for taking the time to do this particular step of retraining the whole GPT-2 model for Dutch text and put the weights for free on the World Wide Web (and publish a paper). The model is published on the model hub from Huggingface.
The Dutch GPT-2 package consists of two parts. The GPT-2 model consisting of all the weights, and a tokenizer containing the vocabulary and their embeddings which is used by the GPT-2 model to read the input and produce the output. Without a tokenizer it will become really hard to understand the output unless you are a machine (like the tokenizer, so go for the tokenizer).
A Transformer model like GPT-2 model is only capable of interpreting numbers and not strings, like a horoscope dataset. Therefore we need to tokenise the horoscope dataset in order to make sure the model can understand the input.
Tokenization
A tokenizer maps the different words, if present in the vocabulary of the tokenizer, to a number. Whenever a word is not found in the vocubalary, a special token is used to impute the missing number (this is called the “unkown-token”). There are other tokens available like the “beginning-of-sentence-token”, “end-of-sentence-token” and the “padding-token”. In this article we will skip the begin and end of sentence tokens (GPT-2 does not really care about your sentences) but we will make use of the padding token.
A GPT-2 model is a deep learning approach and needs a static input, a fixed length of the input text to train on. Whenever this length does not match the suspected input requirements, the model will explode. Therefore, it is mandatory to make a decision on the length of the input. I decided to look at the distribution of the lengths of every horoscope from the original dataset to set the maximum length for the input per horoscope.
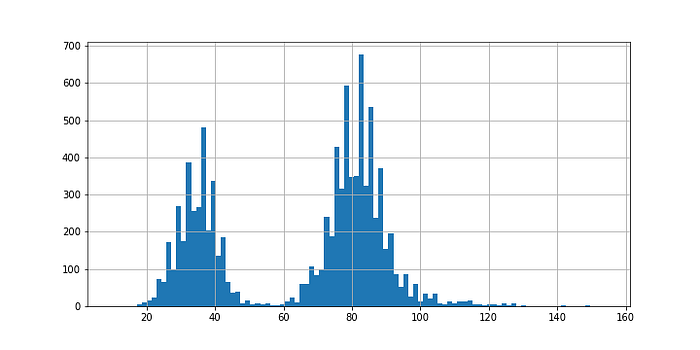
As you can see, it’s not a normal distrubition. Whenever I would take the mean of 65 words per horoscope as the maximum input size (yes, I obviously did this first) I would miss out half of my dataset. By using just my eyes I decided to cap the maximum amount of words to 100.
But what if some of the horoscopes do not meet the requirements? Here comes the padding-token into play. Every text smaller than 100 will be padded by filling in every spot with the set padding-token.
The GPT2Tokenizer is instantiated by using the right link to the model on the Huggingface hub. I add a special token for the padding process. I choose to go for the highly creative token: <pad>. In fact, you can pick everything you want there since the string is mapped to an integer anyway. A function is created to map tokenize every text and making sure it will have a length of 100. I hear you asking; what happens with horoscopes with a total over 100 words? That is why truncation is set to True in the arguments of the tokenizer, every word above the length of 100 words will just be left behind (that’s life). The map method is used to map every instance of the Dataset object in both sets to the tokenizer function. To be as clear as possible, here is a quick and dirty example to showcase the output of such a tokenizer:
As the example shows, the tokenizer first splits the full string into tokens. To make the tokens readable for a Transformer like the GPT-2 model, the tokens need to be converted to numbers. Both steps are done automatically when calling the tokenizer (see the coding example above).
Adding labels to the dataset
Before jumping into the fine-tuning phase it is time to adjust the current horoscope dataset by adding some labels. Labels? But a GPT-2 model is self-supervised right? True, but still it needs to have an objective when training. The logic of self supervising is done within the model. Therefore, the solution is quite easy.
This code adds another key named “labels” to the features set for every example in the Dataset object by applying the same strategy when tokenizing. The contents of the “labels” should be the same as the contents of the “input_ids”. We are finally ready to start training and create some holistic horoscopes.
Retraining the pre-trained model
Time for the real nerdy work. We are ready to instantiate a GPT-2 model, load the weights which I legally stole from the champions from the University of Groningen and hit the big red button. But only after we first resized the vocabulary as we added an extra token (remember the “padding” one?). That is done quite easily by resizing the token embeddings of the model (and checking if the sizes of both vocabularies are indeed the same). The original model contained 40000 known tokens so by adding one, the result would be 40001 tokens inside the vocabulary of the model.
One thing might be good to know here: there are different classes to be found in the Huggingface framework for the GPT-2 model. One of them is the plain GPT2Model class but this one is too abstract for easy usage. That is the reason the framework also provides a GPT2LMHeadModel class which includes a LMHead layer, which (in short) helps us retrieve “readable” output. The model outputs an extra layer which contains the probability for every token (node) known in the vocabulary of the model (and thus tokenizer). This means that the probabilities of all of the 40001 tokens will sum to one. Without this so-called “dense” layer, I would be far from home and wouldn’t be able to use the output of the model to generate text, but I’ll cover this output representation later in more detail (if you didn’t already close your browser yet).
The fine-tuning of the model by adding a custom dataset can be done in various ways by the variability of the possible settings. Huggingface provides a TrainingArguments class which can be used as an argument for the Trainer class, which is used for the actual training.
This setup will compute five epochs of the train set (full rounds of all the examples). Every step (to recompute the weights) will contain 16 examples and every step when doing an evaluation on the test set will contain 64 examples. Every 25 steps the training loss will be computed and logged, same rules apply for the validation step.
By instantiating a Trainer class with the pre-trained model and the just made settings it is time to use the custom dataset to start fine-tuning. The validation set will be used to validate the training steps with a smaller dataset by computing the loss function. The test set will be used to validate the model whenever it has finished fine-tuning by computing the loss over the whole test set. The loss function used within the GPT-2 model is the cross-entropy loss (the lower the number, the better) and is used for all loss calculations. Call the Trainer object by using the function train. I added a EarlyStoppingCallback to the Trainer instance with a “patience” set to 3. Whenever the validation loss did not improve for three times in a row, the training will stop and the best step will be loaded into the trainer variable. The result of the training phase is plotted below.
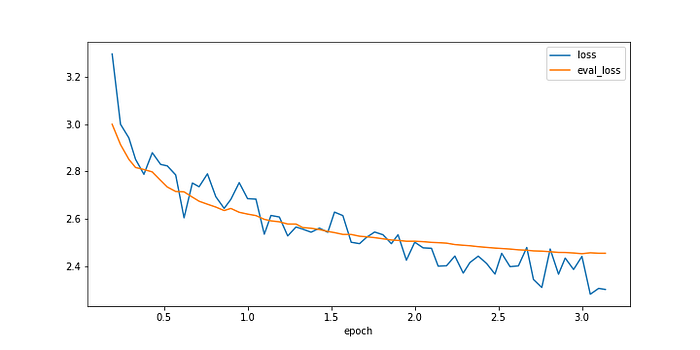
The training stopped due to the early stopping trigger at step 1650 (epoch 3.14). The validation loss on the test set is 2.452 while the training loss on the training set equals 2.301. The model seems also to be performing well on the validation set, conluding: the model is not overfitting on the training data. The model is ready. The loss could have been less with more training steps (i.e. more epochs), but the gains become less and less, with the loss converging to some point. In addition, this obviously is a trade-off between computation time and the loss, and since this experiment already took eight hours, I decided to call it a day.
Generating new horoscopes written in Dutch
Time for the real deal: generating text using our the model and hoping the text comes out as horoscope as possible. The Huggingface ecosystem provides an API to easily generate text by only loading the model, the tokenizer and providing a context. The context is necessary as this will be used as the first input for the GPT-2 model. This input will be used by the model to predict the next best word within the vocabulary based on the probabilities for every token. There are different ways to select the best output from the list of probabilities, for instance picking a random token from the 10 tokens with the highest probabilities. The winning output will be added to the original input and this process is recursive until the maximum length of the text is reached. An in-depth and great explanation how text is generated using the pipeline API can be found in a blogpost on the Hugging Face website.
A pipeline object is instantiated by setting the objective of the pipeline to “text-generation” in order to generate text. The model that was computed was saved to the folder “model” within the current folder and that is the exact model that should be loaded into the pipeline. The tokenizer is the same as the one of the pre-trained model. The pipeline returns a function which can be used to generate outputs by just calling the variable. By calling this function with a context the model will generate the rest of the text. The context could be either the start of a text or a question by adding a question mark (the model is capable of recognising a question).
“Ga ik nog een artikel schrijven? Dat is niet verstandig. Ga er eerst iets nieuws over verzinnen, dan komt het vanzelf goed. Dan ben je helemaal in staat nieuwe indrukken aan te komen. Je bent ontzettend enthousiast en dat wordt ook wel eens extra gewaardeerd. Het zou geen kwaad kunnen om die ene belangrijke uitgave voor de volgende keer uit te gaan. Een paar dagen later kun je alles weer bij elkaar krijgen wat jij zo hard wilt doen. En daar heb je nu echt niets mee te maken.” (English translation)
